AI, 검색엔진, 챗봇과 연동되는 전자책 플랫폼
리프아이티의 e-Book 기술은 단순히 전자책을 보여주는 뷰어에서 그치지 않습니다.
고객사가 운영하는 AI, 챗봇, 검색엔진 시스템과 직접 연동할 수 있는 구조로 설계되어 있습니다.
기관 내부에 축적된 모든 전자책, e-Book의 본문 텍스트는 데이터베이스에 정제된 형태로 저장되며, 표준화된 검색 API를 통해 외부 AI나 챗봇이 이 데이터를 안전하게 참조하고 활용할 수 있습니다. 도입 기관은 별도의 문서 수집, 가공 과정 없이 기존 전자책 콘텐츠를 그대로 AI 지식 데이터로 전환할 수 있습니다.
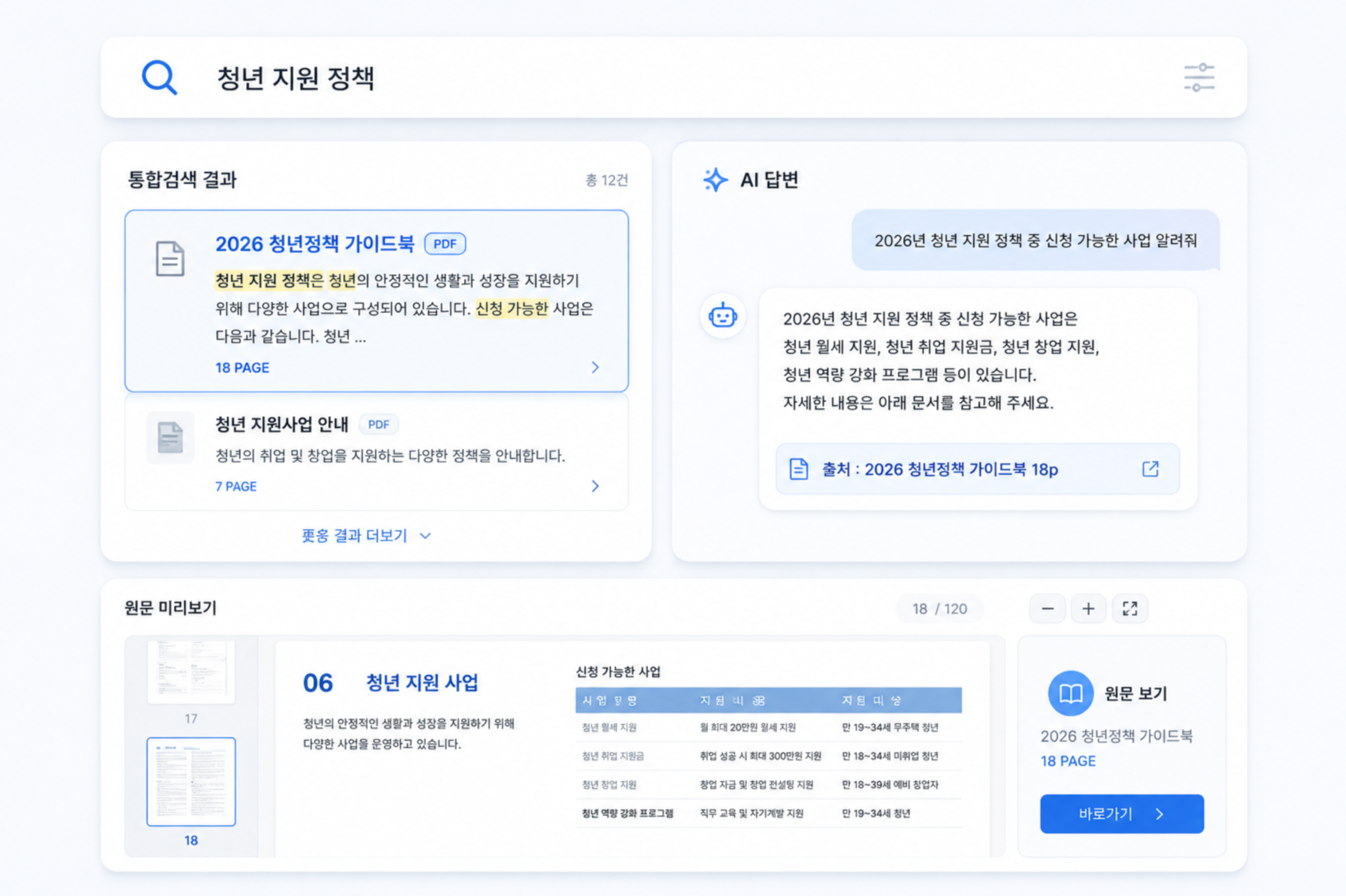
대표 홈페이지 검색부터 챗봇 AI까지 : 실제 활용 시나리오
기관 대표 홈페이지 검색창에서 “새로운 정책”, “연구성과”, “학사 일정” 같은 키워드를 입력하면, 일반 게시판이나 공지사항뿐 아니라 e-Book 본문 내부 내용까지 함께 검색 결과에 표시될 수 있습니다.
사용자는 검색 결과를 통해 관련 문서의 특정 페이지로 바로 이동할 수 있으며, 필요한 정보를 찾기 위해 수십 페이지의 PDF를 직접 열어볼 필요가 없습니다. 이 구조는 챗봇 AI와도 연결될 수 있습니다.
예를 들어 사용자가 챗봇에 다음과 같이 질문합니다.
“2026년 청년 지원 정책 중 신청 가능한 사업 알려줘”
챗봇은 e-Book 본문 데이터를 기반으로 답변을 생성하고, 단순 답변만 제공하는 것이 아니라 다음과 같은 출처 정보까지 함께 제공합니다.
- 참조 문서명
- 페이지 번호
- 원문 바로가기 링크
- 인용된 본문 내용
즉, AI는 "대답만 하는 구조"가 아니라, 기관 내부 문서를 근거로 응답하고 사용자가 직접 검증할 수 있는 형태입니다.
리프아이티 e-Book 플랫폼은 전자책을 단순 열람 자료로 보지 않습니다. 검색, AI, 챗봇, 통합 포털과 연결 가능한 기관형 문서 데이터 플랫폼 구조를 목표로 설계되고 있습니다.
단순 뷰어를 넘어선 문서 인프라
많은 e-Book, 전자책 솔루션이 내용을 ‘보여주는 것’에 집중합니다. 리프아이티는 처음부터 다른 방향을 택했습니다. 문서파일을 업로드하는 순간, 단순 파일 저장이 아니라 구조화된 데이터 처리가 시작됩니다.
문서 처리 흐름
- 파일 업로드 → 텍스트 추출 → 페이지 단위 DB 저장
- e-Book ID 기반 문서 식별 체계 구성
- 페이지 번호와 본문 텍스트의 1:1 매핑 구조 유지
- 검색 전용 데이터 계층(View) 분리 운영
- 표준화된 검색 API를 통한 외부 시스템 연계
이 구조의 핵심은 원본파일에서 추출된 본문 텍스트 데이터를 검색과 AI 연계에 함께 활용할 수 있도록 설계되어 있다는 점입니다.
e-Book ID, 페이지 번호, 본문 텍스트가 연결된 상태로 저장되기 때문에, 검색 결과와 AI 응답 모두 원문 페이지와 자연스럽게 연결될 수 있습니다. 이를 통해 검색 정확도와 응답 신뢰성을 유지하면서도 기존 e-Book 운영 구조를 그대로 활용할 수 있습니다.
OCR이 아닌 원본 텍스트 — 품질에서 시작되는 차이
AI 기반 문서 검색에서 가장 중요한 것은 입력 데이터의 품질입니다. OCR(광학 문자 인식) 방식은 이미지에서 텍스트를 추출하는 특성상 오인식, 줄바꿈 오류, 표 구조 왜곡이 빈번하게 발생합니다. 이렇게 오염된 데이터는 검색 정확도를 낮추고, AI 응답의 신뢰성도 떨어뜨립니다.
리프아이티 전자책 기술은 원본 텍스트 스트림을 직접 추출합니다. 문서가 처음 제작될 때 포함된 실제 텍스트 데이터를 그대로 활용하기 때문에, 검색 인덱스와 AI 학습 데이터 모두 높은 품질을 유지합니다. 정확한 데이터에서 정확한 검색이 나옵니다.
이미 운영 중인 검색 API — 개념이 아닌 현실
리프아이티 e-Book 솔루션에는 표준화된 콘텐츠 검색 API 제공이 가능합니다. 일반적인 키워드 검사를 넘어, 실무 환경에서 요구되는 다양한 검색 조건을 파라미터로 제어할 수 있습니다.
리프아이티 e-Book 플랫폼은 본문 텍스트 데이터를 기반으로 다양한 검색 조건을 조합할 수 있는 검색 API를 제공합니다.
GET /Web/search/key={leafit_key}&요청변수
- 본문 및 제목 기반 검색
- 다중 키워드 AND / OR 조건 검색
- 특정 콘텐츠 또는 제작자 범위 제한 검색
- 검색 키워드 하이라이트 표시
- 출력 결과 수 및 페이지 단위 제어
이 API는 홈페이지 통합검색, 기관 포털, AI 챗봇, RAG 엔진 등 어떤 외부 시스템이든 동일한 API 엔드포인트 하나로 연계할 수 있습니다. 시스템이 바뀌어도 API 구조는 유지되므로, 장기 운영 관점에서도 안정적입니다.
AI가 파일을 직접 읽지 않습니다 — 검색 API 기반 연계 구조
AI 연계 구조를 설계할 때 흔하게 발생하는 리스크는 원본 DB나 파일에 직접 접근하도록 구성하는 것입니다. 운영 데이터에 대한 무분별한 접근은 보안 문제와 성능 저하로 이어질 수 있습니다.
리프아이티 e-Book 플랫폼은 검색 API를 중심으로 외부 시스템과 연계되는 구조를 사용합니다.
데이터 흐름
- 원본 파일 → 텍스트 추출 → 데이터 저장
- 텍스트 데이터 → 텍스트 API 제공
- 텍스트 API → 챗봇 / AI / 검색엔진 연계
AI와 외부 시스템은 텍스트 API를 통해 필요한 데이터만 참조합니다. 이 과정에서 비공개 문서, 권한 제한 자료, 개인정보가 포함된 콘텐츠를 검색 대상에서 제외할 수 있어, 기관이 AI에 노출되는 데이터를 직접 통제할 수 있습니다.
이 구조는 AI 모델이 변경되더라도 그대로 유지가 가능합니다.
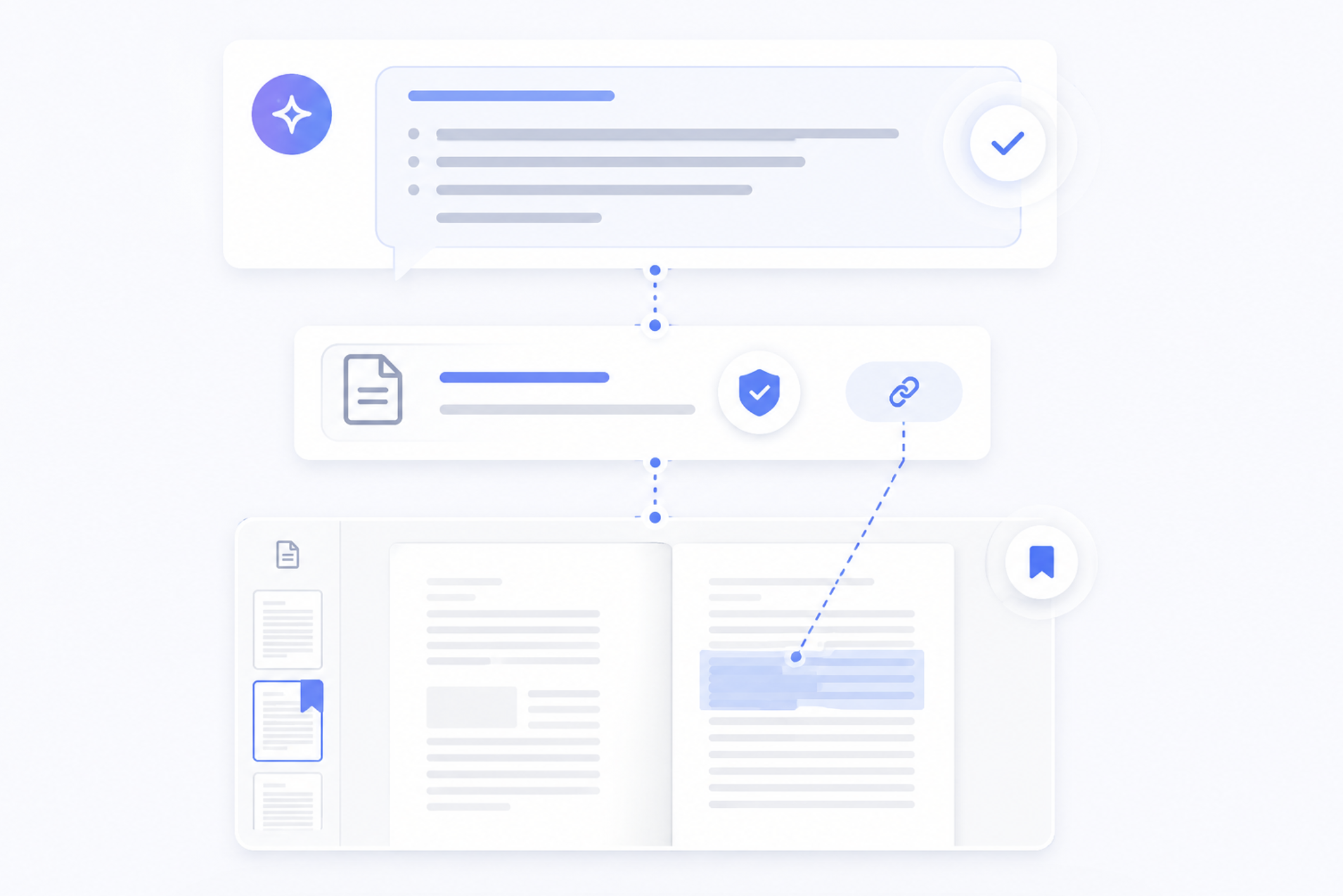
답변에 출처가 따라옵니다 — 페이지 딥링크 연동 구조
일반적인 AI 챗봇의 가장 큰 약점은 출처 불명과 환각(Hallucination) 입니다. 답변이 그럴듯해 보여도 어디서 나온 정보인지 확인할 방법이 없습니다. 특히 학사 안내, 정책 문서, 연구 자료처럼 정확성이 중요한 기관 문서에서는 치명적인 문제입니다.
리프아이티의 구조는 이 문제를 구조적으로 해결합니다.
모든 본문 텍스트는 e-Book ID와 페이지 번호가 매핑된 상태로 저장되어 있습니다. AI가 특정 내용을 참조해 답변을 생성하면, 해당 답변의 근거가 된 문서명과 페이지를 함께 제공하고, 사용자는 클릭 한 번으로 원문 페이지로 바로 이동할 수 있습니다.
“2026년 소상공인 지원사업 신청 조건 알려줘”
→ AI 응답 + “2026 소상공인 지원정책 안내서 27페이지 참고” + 원문 바로가기
이 구조는 산재되어 있는 데이터만 학습한 챗봇이 제공할 수 없는 검증 가능한 AI 응답입니다. 기관 담당자 입장에서도, 도입 결정을 내리는 관리자 입장에서도, 이 차이는 신뢰의 문제입니다.
권한이 있는 사람에게만, 권한 범위 내 문서만
기관 환경에서 AI 도입을 망설이는 이유 중 하나는 정보 접근 통제 문제입니다. AI가 모든 문서를 학습하고 누구에게나 동일하게 응답한다면, 내부 보안 정책과 충돌하게 됩니다.
리프아이티의 텍스트 API는 사용자 ID와 e-Book ID 기반 접근 제한을 지원합니다. 특정 사용자 또는 그룹에게 허용된 문서의 범위 내에서만 검색 결과가 반환되며, AI 역시 그 범위 안의 데이터만 참조합니다.
- 일반 사용자 → 공개 문서 범위 내 응답만 제공
- 비공개 처리된 문서 → 검색 및 AI 참조에서 완전 제외
AI가 독립 시스템이 아니라 문서 권한 체계 안에서 작동하는 구조입니다.
RAG 구조로 확장 가능한 기반 아키텍처
최근 AI 분야에서 가장 주목받는 기술 중 하나가 RAG(Retrieval-Augmented Generation)입니다. LLM이 자체 학습 데이터만으로 답변하는 것이 아니라, 실제 문서 저장소에서 관련 내용을 검색해 참조한 뒤 응답을 생성하는 방식입니다. 환각 문제를 줄이고 최신 내부 자료를 반영할 수 있어, 기관형 AI 구축의 핵심 기술로 자리잡고 있습니다.
리프아이티의 e-Book 플랫폼은 이 RAG 구조와 자연스럽게 결합됩니다.
- 문서 저장소 : 전자책 본문 텍스트가 이미 존재
- 검색 인덱스 : 페이지 단위 구조화 데이터 보유
- API 레이어 : 외부 AI 시스템이 참조할 검색 인터페이스 운영 중
여기에 벡터 DB와 임베딩 모델을 연결하면, 단순 키워드 검색을 넘어 의미 기반 검색(Semantic Search)과 질의응답형 AI(Document QA) 구조로 발전할 수 있습니다. 새로 시스템을 구축하는 것이 아니라, 기존 인프라를 확장하는 방식입니다.
기관형 지식검색 플랫폼으로의 전환
대학교의 학사자료, 공공기관의 정책집과 백서, 기업의 매뉴얼과 연구보고서.
이 문서들은 지금 이 순간에도 파일 형태로 저장소 어딘가에 잠들어 있습니다. 검색되지 않고, 질문을 받지 못하고, 활용되지 못한 채로.
리프아이티의 e-Book 기술은 이 문서들을 살아있는 지식 데이터로 전환합니다.
- 전자책을 등록하는 순간 검색 가능한 데이터가 됩니다
- 축적된 데이터는 API를 통해 AI가 참조할 수 있는 지식 베이스가 됩니다
- AI의 답변은 원문 페이지로 연결되어 검증 가능합니다
- 모든 과정이 기관 내부 보안 정책 안에서 통제됩니다
20년 가까이 전자책 솔루션을 납품하고 운영해 온 리프아이티가 AI 시대에도 같은 방향을 유지하는 이유는 하나입니다. 문서를 제대로 다루는 것, 그것이 모든 기술의 출발점이기 때문입니다.
Technical Keywords
리프아이티 e-Book 솔루션 텍스트 API AI 챗봇 연동 RAG 문서 기반 AI 텍스트 추출 Full-text Search Semantic Search 기관형 AI 지식검색 플랫폼 온프레미스 AI 전자책 검색 문서 AI 검색 AI 검색 시스템
작성자 : (주)리프아이티 ICT사업본부